![]() If the dataset you want to analyze with pandas is coming from a normalized relational database, then you can use ‘pandas.read_sql‘ to pull the data directly.
If the dataset you want to analyze with pandas is coming from a normalized relational database, then you can use ‘pandas.read_sql‘ to pull the data directly.
In this article, we will deploy a small MariaDB instance with Docker and show how we can create DataFrame directly from a single table or from a join between multiple tables.
Prerequisites
Install Docker, here is an article I wrote for installation on Ubuntu focal 20.04.
Deploy MariaDB from Docker image
# pull down image from dockerhub
sudo docker pull mariadb:10.7.1-focal
# image now available, 411Mb
sudo docker images | grep mariadb
# run MariaDB in background
sudo docker run --name mariadbtest -e MYSQL_ROOT_PASSWORD=thepassword -d mariadb:10.7.1-focal
# show logs
sudo docker logs mariadbtest
# get IP address where database can be reached at port 3306
# will be on 172.17 docker network
export dbIP=$(sudo docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mariadbtest)
echo "MariaDB listening on $dbIP:3306"
Smoke test DB from inside container
There is a mysql client inside the container that we can use to smoke test the database.
# get a shell to inside the DB container sudo docker exec -it mariadbtest bash # connect, show list of databases # there is purposely no space between 'p' flag and password mysql -u root -pthepassword -e "show databases" # connect to 'mysql' database, show tables mysql -u root -pthepassword -e "use mysql;show tables;" # exit the container, back to host exit
Smoke test DB with local client
Now that we know the IP address of the MariaDB container, we can connect directly from our host.
sudo apt install mariadb-client -y # netcat to prove connection to port 3306 nc -vz $dbIP 3306 # connect, show list of databases # should produce the exact result as section above mysql -h $dbIP -u root -pthepassword -e "show databases;"
This proves we have host -> docker container connectivity on port 3306. We needed to prove this out because pandas will be making a similar connection for its work later.
Create Database and load data
Create a custom “employees” database where we will load our schemas and data. We will perform these operations from our host, using the mysql client to connect.
# same arguments used for multiple commands mysql_prefix="mysql -h $dbIP -u root -pthepassword" # create custom database $mysql_prefix -e "create database employees;" # custom database should now be available $mysql_prefix -e "show databases;"
Then download the sample Employees Database.
cd ~/Downloads # download and unzip wget https://github.com/datacharmer/test_db/releases/download/v1.0.7/test_db-1.0.7.tar.gz tar xvfz test_db-1.0.7.tar.gz # load into mysql cd test_db # load all schema and tables $mysql_prefix -D employees < employees.sql INFO CREATING DATABASE STRUCTURE INFO storage engine: InnoDB INFO LOADING departments INFO LOADING employees INFO LOADING dept_emp INFO LOADING dept_manager INFO LOADING titles INFO LOADING salaries data_load_time_diff 00:01:41
Then show the tables that have been created.
# show tables $mysql_prefix -D employees -e "show tables;" +----------------------+ | Tables_in_employees | +----------------------+ | current_dept_emp | | departments | | dept_emp | | dept_emp_latest_date | | dept_manager | | employees | | salaries | | titles | +----------------------+
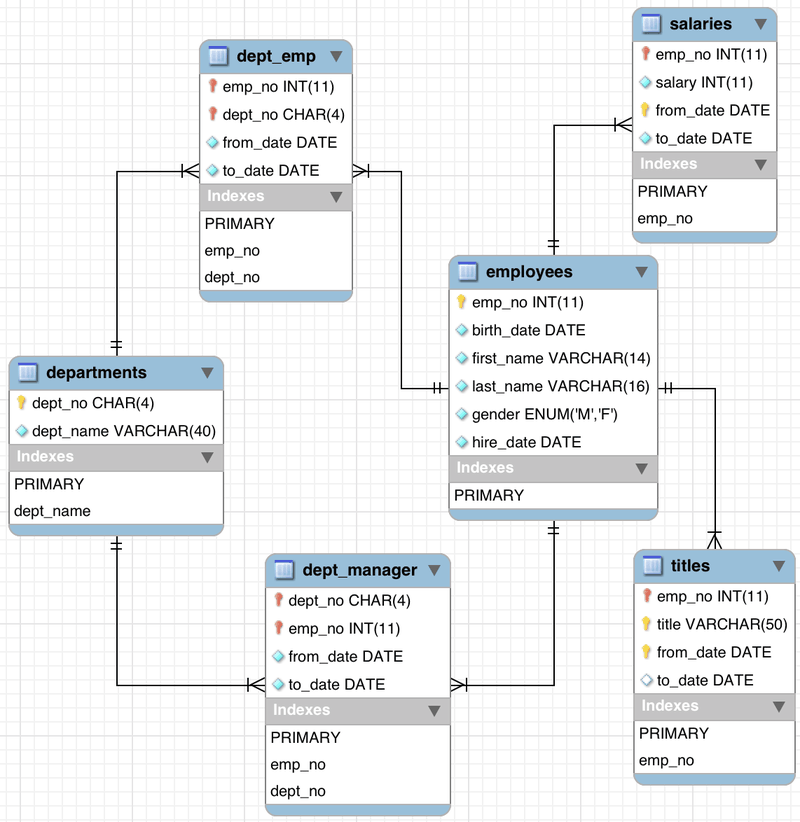
Database schema explained
A diagram of the database schema is shown below. We will be using pandas in the next sections to get a flattened out view of all the employees in a single department and their titles; which requires flattening out these tables: departments, dept_emp, employees, and titles.
You can write a single SQL with joins to get this view, OR you can have pandas merge DataFrames based on ids. We will show both methods and discuss the differences afterwards.
Install Python3 modules
Make sure the pandas and mysql modules are installed and available to Python3.
# pandas pip3 install pandas --user # mysql connector pip3 install mysql-client mysql-connector --user
Run Python3 pandas script
Before I explain the critical pieces of code, let’s run the script and view the final results.
Remember, our goal was to flatten out the employee table with additional information on job title, while only showing employees in the ‘Finance’ group.
# get script from github, set executable permissions
$ wget https://raw.githubusercontent.com/fabianlee/blogcode/master/pandas/mariadb/analyze_employees_in_database.py3
$ chmod +x analyze_employees_in_database.py3
# pull from live MariaDB database
$ ./analyze_employees_in_database.py3
=================================================
1. DataFrame using single SQL with complex join
=================================================
dept_no dept_name emp_no first_name last_name title
0 d002 Finance 10042 Magy Stamatiou Senior Staff
1 d002 Finance 10042 Magy Stamatiou Staff
2 d002 Finance 10050 Yinghua Dredge Senior Staff
3 d002 Finance 10050 Yinghua Dredge Staff
4 d002 Finance 10059 Alejandro McAlpine Senior Staff
... ... ... ... ... ... ...
26065 d002 Finance 499975 Masali Chorvat Staff
26066 d002 Finance 499977 Martial Weisert Staff
26067 d002 Finance 499989 Keiichiro Lindqvist Senior Staff
26068 d002 Finance 499998 Patricia Breugel Senior Staff
26069 d002 Finance 499998 Patricia Breugel Staff
[26070 rows x 6 columns]
=================================================
2. Multiple DataFrame merged by pandas
=================================================
Select department info for each employee in Finance...
Select titles just for Finance group..
Select employees in Finance...
dept_no dept_name emp_no dept_no_e last_name first_name title
0 d002 Finance 10042 d002 Stamatiou Magy Senior Staff
1 d002 Finance 10042 d002 Stamatiou Magy Staff
2 d002 Finance 10050 d002 Dredge Yinghua Senior Staff
3 d002 Finance 10050 d002 Dredge Yinghua Staff
4 d002 Finance 10059 d002 McAlpine Alejandro Senior Staff
... ... ... ... ... ... ... ...
26065 d002 Finance 499975 d002 Chorvat Masali Staff
26066 d002 Finance 499977 d002 Weisert Martial Staff
26067 d002 Finance 499989 d002 Lindqvist Keiichiro Senior Staff
26068 d002 Finance 499998 d002 Breugel Patricia Senior Staff
26069 d002 Finance 499998 d002 Breugel Patricia Staff
[26070 rows x 7 columns]
Both the first and second set of results provide 26070 rows of data from a DataFrame that provide the desired view.
pandas connection to database
The first step is to create a mysql connection to the MariaDB server.
# connect to MariaDB server
db_conn = mysql.connector.connect(
host=args.host,
user=args.user,
passwd=args.password,
database="employees"
)
# simplest test of DB connection
# executes statement and constructs DataFrame
all_tables = pd.read_sql("show tables",db_conn)
We then run a very simple smoke test by reading in the tables available in the database.
pandas DataFrame from single SQL join
We now want to query the employees table, while also joining the job titles and limiting the results to employees of the Finance group.
Below is the SQL and pandas.read_sql that does the complex join to bring this data into a single DataFrame.
# pull all required data in single complex join
employee_data = pd.read_sql("""
SELECT d.dept_no,d.dept_name,e.emp_no,e.first_name, e.last_name, t.title
FROM employees e
INNER JOIN dept_emp de ON e.emp_no=de.emp_no
INNER JOIN departments d ON d.dept_no=de.dept_no
INNER JOIN titles t ON e.emp_no=t.emp_no
WHERE d.dept_name='{}'
""".format(department_name),
db_conn)
# show DataFrame
print(employee_data)
This returns 26070 rows of data in a DataFrame.
pandas DataFrame from multiple queries
There is another way to approach this problem.You could also run simpler queries, and then using pandas.merge to flatten them out.
dept_info = pd.read_sql("""
SELECT d.dept_no,d.dept_name,de.emp_no
FROM departments d, dept_emp de
WHERE d.dept_name='{}' AND d.dept_no=de.dept_no
""".format(department_name),
db_conn)
titles = pd.read_sql("""
SELECT t.emp_no,t.title
FROM titles t
INNER JOIN dept_emp de ON de.emp_no=t.emp_no
WHERE de.dept_no = (select de.dept_no from departments de where de.dept_name='{}')
""".format(department_name),
db_conn)
employees_from_dept = pd.read_sql("""
SELECT de.dept_no,e.emp_no,e.last_name,e.first_name
FROM employees e
INNER JOIN dept_emp de ON de.emp_no=e.emp_no
WHERE de.dept_no = (select de.dept_no from departments de where de.dept_name='{}')
""".format(department_name),
db_conn)
# merge department and employee data
employees_merged = pd.merge(dept_info,employees_from_dept,how="left",left_on="emp_no",right_on="emp_no",suffixes=(None,"_e") )
# additional merge of titles
employees_merged = pd.merge(employees_merged,titles,how="left",left_on="emp_no",right_on="emp_no",suffixes=(None,"_e") )
# show final merged DataFrame
print(employees_merged)
This second approach with multiple queries/DataFrame and doing the merge in pandas also returns the same 26070 rows.
Choosing an Approach
We saw two different ways of reaching the same goal.
The first used a complex SQL join to construct a single DataFrame from multiple tables. The other constructed multiple DataFrame using simpler queries, then had pandas merge them together.
Which one should you use? The answer is you should use the database to join the data as much as possible. But there are many reasons why the pure SQL approach has to be deviated from at some point:
- Some of your DataFrame come from other data sources (e.g. csv, json, Excel)
- The relational database is huge, and your proposed joins will affect customer performance
- The tables that need to be joined come from different namespaces that cannot be joined
- There are too many tables to join, for either human comprehension or database resources to handle
Destroying MariaDB
# stop and remove sudo docker stop mariadbtest sudo docker rm mariadbtest # check for existence, should be gone now sudo docker ps
REFERENCES
MariaDB, running as Docker container
kifarunix.com, installing and running MariaDB as Docker container
blog.shanelee, import and export databases with MariaDB and Docker
stackoverflow, piping local file to MariaDB docker container for import
mysql.com, Employees Sample DB
Employees Sample DB on github, download.tgz
mysqltutorial.org, sample product database
github, analyze_employees_in_database.py3
NOTES
SQL that groups employee so that number of titles they had is counted
# 17280 rows SELECT d.dept_no,d.dept_name,e.first_name, e.last_name, t.title,count(t.title) FROM employees e INNER JOIN dept_emp de ON e.emp_no=de.emp_no INNER JOIN departments d ON d.dept_no=de.dept_no INNER JOIN titles t ON e.emp_no=t.emp_no WHERE d.dept_name='Finance' GROUP BY e.last_name,e.first_name ORDER BY e.last_name,e.first_name;