![]() No matter how highly available your services, there may still be significant backend events that require planned maintenance. During this downtime, you should still reply to end users and service integrations with a proper response.
No matter how highly available your services, there may still be significant backend events that require planned maintenance. During this downtime, you should still reply to end users and service integrations with a proper response.
In this article, I will show you how to configure your GCP HTTPS Loadbalancer so that a single maintenance service responds to all requests with a custom maintenance web page.
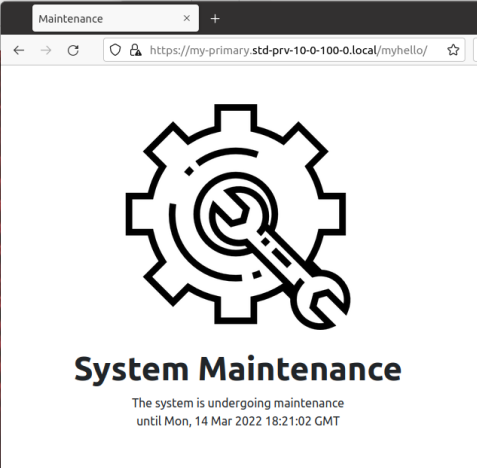
Instead of returning a normal HTTP response code of 200, this page will instead send a 503 “Server Unavailable” so that API consumers and integrations also understand this is a server-side outage.
Solution Overview
The first step is to create our custom maintenance service that delivers a single custom web page no matter what context or parameters are sent. NGINX is a proven and scalable solution for serving content, so we use that to deliver our custom web page and code.
Then, we need to configure the GCP HTTPS LB so that it sends all requests to this custom maintenance service. We do this by making only a single rule for the loadbalancer, and that rule uses container native routing to send all requests to our custom maintenance service.
With these in place, we then wait the for a refresh of the HTTPS LB configuration. When done, all requests going through the LB will be served the custom maintenance web page.
Custom Maintenance service
Although I could have written a simple golang webserver or python flask app to deliver a custom web page, I think the better solution is to simply use a proven and scalable server like NGINX.
We use a small Alpine-based NGINX instance, and populate our custom “/etc/nginx/nginx.conf” using a ConfigMap and volumeMounts.
For the custom web page we take a similar approach and create a ConfigMap with custom HTML that uses a VolumeMount to expose it at “/usr/share/nginx/html/maintenance.html”.
The nginx.conf does the heavy-lifting of the logic, exposing a “/healthz” endpoint that returns 200 for health checks and sending all other requests to our custom “/maintenance.html” with a 503 return code.
# for kubernetes health check
location = /healthz {
add_header Content-Type text/plain;
return 200 'OK';
}
# anything else sends 503 server unavailable
location / {
return 503;
}
# handler for 503 errors
error_page 503 @maintenance;
location @maintenance {
rewrite ^(.*)$ /maintenance.html break;
}
The full deployment yaml is on github as nginx-maintenance-service.yaml. You can deploy using:
kubectl apply -f https://raw.githubusercontent.com/fabianlee/gcp-gke-clusters-ingress/main/roles/nginx-maintenance/templates/nginx-maintenance-service.yaml
Configure GCP HTTPS LoadBalancer
To capture all requests and send them to our custom maintenance service, we will modify the Ingress object which configures the external HTTPS Loadbalancer.
We will set a single rule on the Ingress that sends “/*” to our service as shown below.
spec:
rules:
- http:
paths:
- path: /*
pathType: ImplementationSpecific
backend:
service:
name: nginx-maintenance-service
port:
number: 8080
See my full ingress-maintenance.yaml.
Testing
It takes between 2-5 minutes for the Ingress configuration changes to synchronize to the HTTP LB. When it does, you will get a page like below in your browser, no matter what request path or parameter you send.
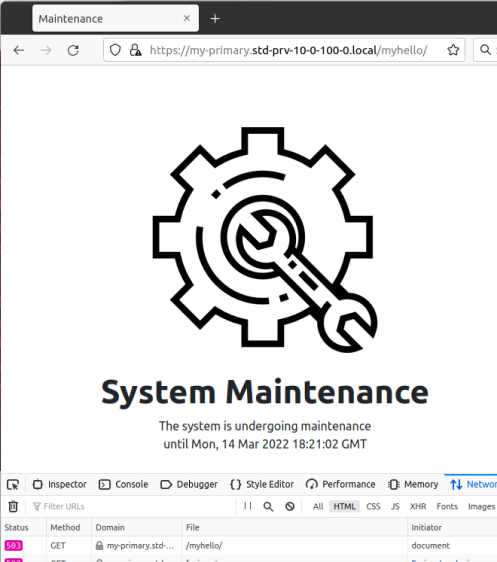
Per the network trace at the bottom of this screenshot, you can see that a 503 is returned, which signals to users and systems the service unavailability.
Note that you may see 2-5 seconds of generic 502 error coming from the HTTPS LB right before the custom maintenance service starts delivering content.
REFERENCES
google, ingress for external load balancing with container native routing
joergfelser.at, 503 nginx maintenance page
google, http lb tutorial with 2 rules
google, exposing service mesh apps through gke ingress
cyral.com, container native loadbalancing with GKE
google, limitations of internal HTTPS LB