![]() The ELK stack (ElasticSearch-Logstash-Kibana), is a horizontally scalable solution with multiple tiers and points of extension and scalability.
The ELK stack (ElasticSearch-Logstash-Kibana), is a horizontally scalable solution with multiple tiers and points of extension and scalability.
Because so many companies have adopted the platform and tuned it for their specific use cases, it would be impossible to enumerate all the novel ways in which scalability and availability had been enhanced by load balancers, message queues, indexes on distinct physical drives, etc… So in this article I want to explore the obvious extension points, and encourage the reader to treat this as a starting point in their own design and deployment.
Overview
Let’s start with the simplest logical deployment for ELK, which is a data source on the left, flowing through a Logstash indexing layer that filters and extracts the data, an ultimately sends it to Elasticsearch for indexing/searching. From there, Kibana allows end users to analyze the data using a web application.
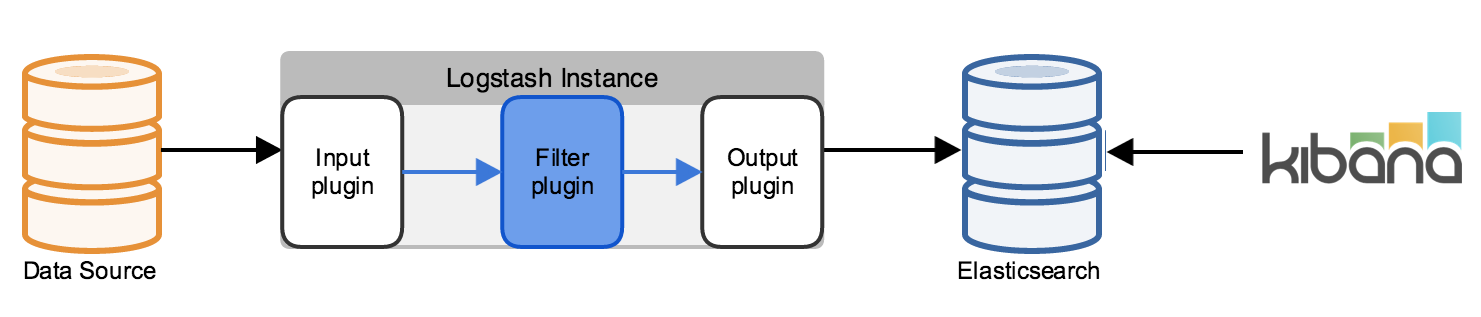
Immediately, questions should come to mind. Where is the clustering that would allow Elasticsearch or the Logstash indexing layer to be highly available or scalable? How will we horizontally scale the Logstash Indexing layer which will be executing CPU-intensive regular expression operations to extract fields? By what mechanism will log files be sent to Logstash? Will we lose log events if one of the Logstash nodes goes down?
Instead of trying to address all these in a single article, I’ll break down the flow and describe each in its own post:
ELK: Feeding the logging pipeline
ELK: Performance of the Logstash Indexing layer
ELK: Scaling an ElasticSearch Cluster
ELK: Pointing Kibana to a Client Node
ELK: Federated Search with a Tribal node
Capacity Planning
You may notice that these articles took on architectural decisions and never specific questions like, “How many Logstash instances do I need if I have 10k events/second and my regular expression looks like…”. I’m a firm believer that the only way to determine that is to run real-world load testing in the exact or comparable environment.
If you have a gut feeling that inserting a Logstash shipping layer would make a significant difference in your environment, then take a baseline measurement of performance before/after and prove it. Data driven decisions are always superior to premature optimization with no quantitative proof.
Rally is the benchmark tool released by Elastic.co. There are also JMeter tests and the Elasticsearch Stress Test available on github.
REFERENCES
https://www.elastic.co/guide/en/logstash/current/deploying-and-scaling.html
http://logz.io/blog/deploy-elk-production/
http://engineering.viki.com/blog/2015/log-processing-at-scale-elk-cluster-at-25k-events-per-second/
http://www.slideshare.net/LucasEwalt/elasticsearch-logstash-and-kibana-at-scale